Python is like the king of programming languages, especially in data science and machine learning. It’s popular because it’s easy to learn and has a ton of tools to help you do cool stuff. In fact, there are over 137,000 tools (libraries) you can use with Python.
One of the reasons Python is so practical for data science is because it has multiple libraries that help you work with data, make engaging graphs, and do things like machine learning and deep learning.
Also, Python offers a wide array of libraries for data science, and this article focuses on five key areas:
- Basics of Data Science
- Machine Learning
- AutoML
- Deep Learning
- Natural Language Processing
However, there are many other areas we won’t cover here, such as MLOps, Big Data, and Computer Vision. Remember, the order in which we discuss these topics doesn’t imply one is superior to the others.
What are the benefits of using Python libraries?
Python has become super popular for data science, and there’s a good reason why. Using Python for data science comes with numerous advantages.
First off, Python has tons of really powerful libraries and frameworks like NumPy, Pandas, and SciPy. These tools let you do all sorts of things with data, like manipulating it, analyzing it, and creating models from it.
Python is also really easy for beginners to learn because it’s simple and easy to read. But, it’s also super versatile, so even experienced data scientists can use it to make really complex algorithms and workflows.
Another great thing about Python is its big and active community. This means there are lots of resources, tutorials, and support available. Plus, Python can work with other languages and tools, and it can run on different platforms, which makes it a flexible choice for data science projects.
Top 10 Python Libraries Every Data Scientist Should Learn
Here are 10 libraries for data scientists:
TensorFlow
The first library we’ll look at for data science in Python is TensorFlow. TensorFlow is a powerful library designed for high-performance numerical computations.
Additionally, it has a large community of around 1,500 contributors and over 35,000 comments, showing how widely it’s used across various scientific fields.
At its core, TensorFlow is a framework for defining and running computations involving tensors. These tensors are computational objects that eventually produce a value, making TensorFlow great for complex mathematical operations.
Besides that, TensorFlow is particularly useful for applications such as speech and image recognition, text-based applications, time-series analysis, and video detection.
Applications
- Extensively used in data analysis
- Creates powerful N-dimensional array
- Forms the base of other libraries, such as SciPy and scikit-learn
- Replacement of MATLAB when used with SciPy and matplotlib
Key features
- Seamless library management supported by Google.
- Regular updates and new releases for the latest features.
- Complex Numeric Computations are possible in a scalable manner.
- TensorFlow is rich in API’s and provides low-level and high-level stable API’s in Python and C.
- Easy deployment and computation using CPU and GPU.
- Contains pre-trained models and datasets.
- Pre-trained models for mobiles, embedded devices, and production.
- Tensorboard, a kit using TensorFlow’s visualization toolkit to log and track experiments and model training.
- Compatible with Keras – a high-level API of TensorFlow.

NumPy
NumPy is a hugely popular open-source Python library primarily used for scientific computing. Also, its powerful mathematical functions allow for fast computations, particularly with multidimensional data and large matrices.
It’s also a go-to for linear algebra operations. Many developers prefer using NumPy arrays over Python lists because they are more memory-efficient and convenient.
According to the NumPy website, the library was created in 2005, building on earlier work from the Numeric and Numarray libraries.
One of NumPy’s biggest strengths is its open-source nature, released under the modified BSD license, ensuring it will always be free for everyone to use.
NumPy’s development is open and collaborative, with contributions from the NumPy and wider scientific Python community. If you’re interested in learning more about NumPy, you can check out our introductory course.
Applications
- Widely used in data analysis.
- Creates powerful N-dimensional arrays.
- Forms the foundation of other libraries like SciPy and scikit-learn.
- Often used as a replacement for MATLAB when combined with SciPy and matplotlib.
Key Features
- Precompiled functions for fast numerical routines.
- Array-oriented computing for efficiency.
- Supports an object-oriented approach.
- Compact and faster computations through vectorization.

SciPy
SciPy, short for Scientific Python, is a free and open-source Python library used for high-level scientific and technical computations.
With around 19,000 comments on GitHub and a community of about 600 contributors, SciPy is a popular choice for scientific calculations, as it extends NumPy and provides many user-friendly and efficient routines.
Applications
- Multidimensional image operations.
- Solving differential equations and performing the Fourier transform.
- Optimization algorithms.
- Linear algebra.
Features
- Collection of algorithms and functions built on NumPy.
- High-level commands for data manipulation and visualization.
- Multidimensional image processing with the ndimage submodule.
- Built-in functions for solving differential equations.

Pandas
Next in the list of python librabries is Pandas. Pandas (Python data analysis) is a must in the data science life cycle. It is the most popular and widely used Python library for data science, along with NumPy in matplotlib.
With around 17,00 comments on GitHub and an active community of 1,200 contributors, it is heavily used for data analysis and cleaning.
Besides that, Pandas provides fast, flexible data structures, such as data frame CDs, which are designed to work with structured data very easily and intuitively.
Applications
- Extensively used in data analysis.
- Creates a powerful N-dimensional array.
- Forms the base of other libraries, such as SciPy and scikit-learn.
- Replacement of MATLAB when used with SciPy and matplotlib.
Features
- DataFrames for efficient data manipulation with built-in indexing.
- Tools for reading and writing data in various formats, including Excel, CSV, and SQL databases.
- Label-based slicing, fancy indexing, and subsetting for large datasets.
- High-performance merging and joining of datasets.
- A powerful group-by engine for data aggregation and transformation.
- Time series functionality for tasks like generating date ranges and frequency conversion, with the ability to handle domain-specific time offsets.

Matplotlib
Matplotlib has powerful yet beautiful visualizations. It’s a plotting library for Python with around 26,000 comments on GitHub and a very vibrant community of about 700 contributors.
Because of the graphs and plots that it produces, it’s extensively used for data visualization. It also provides an object-oriented API, which can be used to embed those plots into applications.
Applications
- Correlation analysis of variables.
- Visualize 95 percent confidence intervals of the models.
- Outlier detection using a scatter plot etc.
- Visualize the distribution of data to gain instant insights.
Features
- Usable as a MATLAB replacement, with the advantage of being free and open source.
- Supports dozens of backends and output types, which means you can use it regardless of which operating system you’re using or which output format you wish to use.
- Pandas itself can be used as wrappers around MATLAB API to drive MATLAB like a cleaner.
- Low memory consumption and better runtime behavior.
SciKit-Learn
The terms machine learning and scikit-learn are inseparable. Scikit-learn is one of the most used machine learning libraries in Python. Also, built on NumPy, SciPy, and Matplotlib, it is an open-source Python library that is commercially usable under the BSD license. It is a simple and efficient tool for predictive data analysis tasks.
Initially launched in 2007 as a Google Summer of Code project, Scikit-learn is a community-driven project. However, institutional and private grants help to ensure its sustainability.
The best thing about scikit-learn is that it is very easy to use.
Applications:
- clustering
- classification
- regression
- model selection
- dimensionality reduction
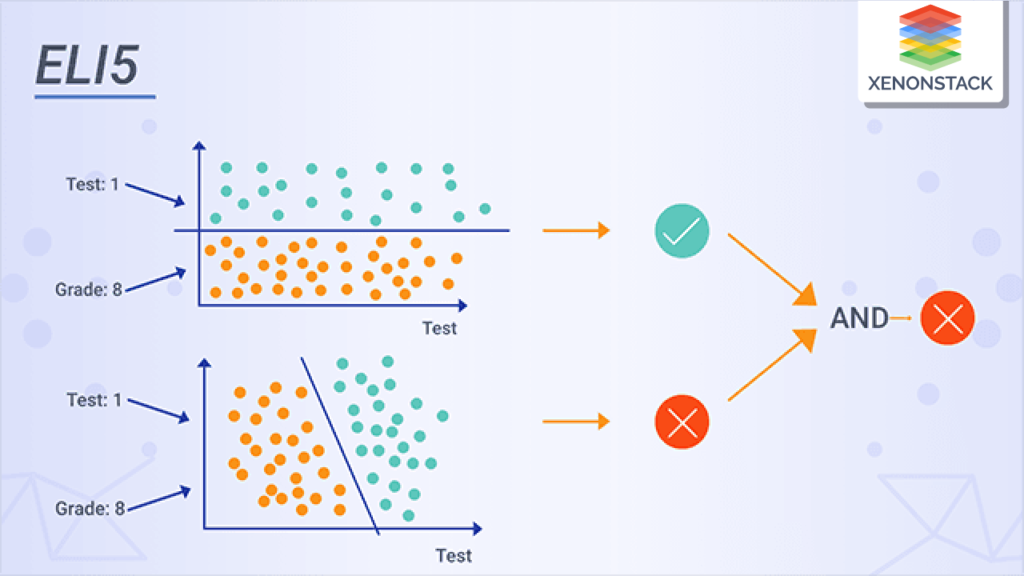
ELI5
ELI5 is a Python library for debugging and visualising machine learning models. It provides tools to help data scientists and machine learning practitioners understand how their models work and diagnose potential problems.
Applications
- Model interpretation.
- Model debugging.
- Model comparison.
Features
- ELI5 provides a range of techniques for interpreting machine learning models, such as feature importance, permutation importance, and SHAP values.
- ELI5 provides tools for debugging machine learning models, such as visualising misclassified examples and inspecting model weights and biases.
- ELI5 can generate human-readable explanations for how a model makes predictions, which can help communicate with non-technical stakeholders.
Keras
Keras is a deep learning API designed for human beings, not machines. It follows best practices for reducing cognitive load:
On top of that, it offers consistent and simple APIs, minimizes the number of user actions required for common use cases, and provides clear and actionable error messages. Moreover, this library is so intuitive that TensorFlow adopted it as their default API in the TF 2.0 release.
It offers a simpler mechanism for expressing neural networks and also includes some of the best tools for developing models, data set processing, graph visualization, and more.
Features
- It runs smoothly on both CPU and GPU.
- It supports nearly all models of a neural network, including convolutional, embedding, pooling, recurrent, etc. These models can also be combined to form increasingly complex models.
- Being modular in nature, Keras is incredibly expressive, flexible, and apt for innovative research.
- It is extremely easy to debug and explore.

PyTorch
PyTorch is a machine learning framework that streamlines the process from research to deployment.
It’s optimized for deep learning with GPUs and CPUs, serving as an alternative to TensorFlow. PyTorch has gained popularity, surpassing TensorFlow on Google Trends.
Developed and maintained by Facebook, PyTorch is available under the BSD license.
Key features
- Seamless transition between eager and graph modes with TorchScript, accelerating the path to production with TorchServe.
- Scalable distributed training and performance optimization supported by the torch.distributed backend.
- A rich ecosystem of tools and libraries for computer vision, NLP, and other fields.
- Extensive support for cloud platforms.
Plotly
Plotly is a widely-used open-source library for creating interactive data visualizations. It’s built on top of the Plotly JavaScript library and allows you to create web-based visualizations that can be saved as HTML files or displayed in Jupyter notebooks and web applications using Dash.
Moreover, Plotly offers more than 40 chart types, including scatter plots, histograms, line charts, bar charts, pie charts, error bars, box plots, multiple axes, sparklines, dendrograms, and 3D charts. One unique feature of Plotly is its support for contour plots, which are not commonly found in other data visualization libraries.
If you’re looking to create interactive visualizations or dashboard-like graphics, Plotly is a great alternative to Matplotlib and Seaborn. It’s available under the MIT license, making it free to use.
How to choose the right Python libraries?
Selecting the right Python library for your data science, machine learning, or natural language processing tasks is important for the success of your projects.
With many libraries available, consider these key factors to make an informed choice:
- Project requirements: Define your goals and tasks, such as data manipulation, visualization, machine learning, or natural language processing.
- Ease of use and learning curve: Look for libraries with user-friendly interfaces, extensive documentation, and rich educational resources.
- Community support: Choose libraries with active communities, frequent updates, and responsive support channels.
- Performance and scalability: Consider the library’s performance with large datasets and complex computations.
- Integration with ecosystem: Ensure compatibility with your existing tech stack and other tools you plan to use.
- License and legal considerations: Understand the licensing terms and ensure they align with your project’s requirements.
- Community feedback and reputation: Look for reviews and testimonials from other developers and data scientists.
- Ongoing maintenance and updates: Choose libraries that are regularly updated and maintained.
- Performance benchmarks: Check performance benchmarks to compare speed and efficiency.
- Consideration of future developments: Look for libraries with clear development plans and future enhancements.
How atomcamp can help you learn Python Libraries?
n conclusion, Python offers a rich ecosystem of libraries that are essential for data science, machine learning, and other fields. From NumPy and Pandas for data manipulation to TensorFlow and PyTorch for deep learning, these libraries provide powerful tools for tackling complex problems.
atomcamp’s data science bootcamp offers a curriculum that covers these libraries and more, helping you master the skills needed to succeed in the field.
With hands-on projects and expert guidance, atomcamp can help you become proficient in these libraries and kickstart your career in data science.